web入门1-10
web入门
1.信息收集
web1

wp:
题目提示:查看源代码
查看网页源代码的几种方式:
1.按F12
2.右键后,查看网页源代码


如图获取得到本题的flag
ctfshow{7e72342c-6236-4013-8691-e176eb4dc45b}
web2

1.首先直接进入题目链接,发现无法直接查看源代码

2.分析为什么不能查看源代码,上网查找资料
使用js脚本禁用了f12和右键
所以解决手段有很多种:
1.题目提示的在url前面加上view-source:
2.浏览器禁用js(不同浏览器的操作不同)
3.ctrl+u直接查看源码,和f12这些快捷方式是一样的,只是本题环境没有禁止
==关于view-source:来查看源代码==
view-source是一种协议,早期基本上每个浏览器都支持这个协议。后来Microsoft考虑安全性,对于WindowsXP pack2以及更高版本以后IE就不再支持此协议。但是这个方法在FireFox和Chrome浏览器都还可以使用。 如果要在IE下查看源代码,只能使用查看中的"查看源代码"命令.
3.题目中有提示,在url前面加上view-source:即可

获得本题flag
ctfshow{cb41a4cf-e31e-4335-9f7c-07dabebc0885}
web3

首先,我们常规思路,查看网站源码

发现没有源码
- 通常的我们使用
==Burp Suite这款中间人工具,对网页进行访问,从而可以实现抓取到访问网页时的数据包,但是在这里我们可以先尝试使用浏览器自带的网络工具查看一下数据包.==
点击F12,点击网络后,按ctrl+r进行刷新,然后在响应头里面找到我们要的flag

第二种按照题目的提示,我们使用burpsuite来进行抓包
暂时还没解决包中乱码的问题
web4

题目中给了robots提示,上网查询了什么是robots.txt?
在谷歌给出的结果是:
Robots.txt文件如何工作?
Robots.txt 文件只是一个没有 HTML 标记代码的文本文件(因此扩展名为 .txt)。robots.txt 文件与网站上的任何其他文件一样,都托管在网络服务器上。实际上,通常可以通过输入主页的完整 URL,然后添加 /robots.txt 来查看任何给定网站的 robots.txt 文件,例如 https://www.cloudflare.com/robots.txt。该文件未链接到网站上的任何其他位置,因此用户不太可能会偶然发现该文件,但是大多数网页爬网程序机器人都会在抓取该网站的其余部分之前先查找该文件。
虽然robots.txt文件提供了有关机器人的规范,但实际上并不能执行这些规范。良性的机器人(例如网页爬网程序或新闻提要机器人)将先尝试访问robots.txt文件,然后再查看域中的任何其他页面,并将按照说明进行操作。恶意的机器人忽略robots.txt文件或对其进行处理,以查找被禁止的网页。
网页爬网程序机器人将遵循robots.txt文件中最具体的指示集。如果文件中有矛盾的命令,则机器人将遵循更细化的命令。
要注意的一件事是,所有子域都需要有自己的robots.txt文件。例如,尽管www.cloudflare.com拥有自己的文件,但所有Cloudflare子域(blog.cloudflare.com,community.cloudflare.com等)也需要它们自己的文件。
于是我们在题目链接后加上robots.txt,于是页面返回如下:

根据返回后的界面我们继续上网查询后,得到
==这是一个robots.txt的详细讲解==

什么是用户代理?“User-agent: *”(用户代理)是什么意思?
在互联网上活动的任何人或程序都将有"用户代理"或分配的名称。对于人类用户,这包括诸如浏览器类型和操作系统版本之类的信息,但不包括个人信息。它可以帮助网站显示与用户系统兼容的内容。对于机器人,用户代理(理论上)可帮助网站管理员了解哪种机器人正在爬网该网站。
在robots.txt文件中,网站管理员可以通过为机器人用户代理编写不同的说明来为特定机器人提供特定说明。例如,如果管理员希望某个页面显示在Google搜索结果中而不显示Bing搜索,则它们可以在robots.txt文件中包含两组命令:一组命令前面带有"User-agent: Bingbot "和另一组前面带有"User-agent: Googlebot" 。
在上面的示例中,Cloudflare在robots.txt文件中包含"User-agent: *" 。星号表示"通配符"用户代理,这意味着该说明适用于每个机器人,而不是任何特定机器人。
通用搜索引擎机器人用户代理名称包括:
Google:
Googlebot
Googlebot-Image(用于图像)
Googlebot-News(用于新闻)
Googlebot-Video(用于视频)
Bing
Bingbot
MSNBot-Media(用于图像和视频)
Baidu
Baiduspider
“Disallow”(禁止)命令在robots.txt文件中的工作原理是什么?
Disallow命令是机器人排除协议中最常见的命令。它告诉机器人不要访问该命令之后的网页或一组网页。不允许的页面不一定是"隐藏的"–它们只是对普通的谷歌或Bing用户没有用,因此不会显示给他们。在大多数情况下,网站上的用户如果知道在哪里可以找到它们,仍然可以导航到这些页面。
Disallow命令可以通过多种方式使用,上面的示例中显示了几种方式。
于是我们继续输入disallow后面的内容,得到

同时得到这道题的flag

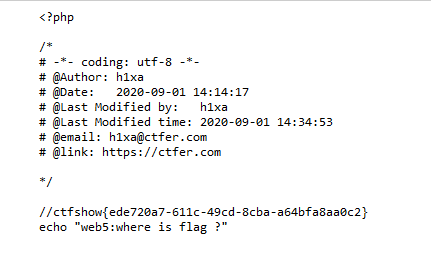
web5

题目提示phps源码泄露
我们尝试查看页面源码,发现右键查看源码和ctrl+u都无法查看源码,包括view-source也无法显示
上网查询phps源码,发现
phps文件就是php的源代码文件,通常用于提供给用户(访问者)直接通过Web浏览器查看php代码的内容。
因为用户无法直接通过Web浏览器“看到”php文件的内容,所以需要用phps文件代替。
于是我考虑在URL后面加上index.phps试试
获得flag
web6

题目给出提示:解压源码到当前目录
1.说明源码压缩包在当前目录下,于是在url后面加上WWW.zip,然后弹出界面下载解压
2.解压后的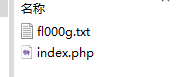
打开第一个文件fl000g.txt后得到

说明flag在这个界面底下
3,于是我们在url后面+fl000g.txt
得到flag
==总结==:关键在知道www.zip,网上给出了两种思路1.扫描软件,扫出来的2.题目给的提示
web7

题目提示看不懂,网上wp
提示用dirsearch来进行扫描,于是去下载
dirsearch
使用python.exe dirsearch.py -h可以查看到各种命令
但前提是在dirsearch.py路径下使用
在本题中,在cmd中输入
python.exe dirsearch.py -u http://2d5c9f25-8981-4f17-b723-0fe947abb5b2.challenge.ctf.show/
得到
所以我们在url后面加上.git
获得flag

web8

题目提示仍然看不懂,看了以下别人wp,在url后面添加index.php.swp
然后出现下载弹窗,下载后打开即可获得flag
关于index.php.swp,上网查询后得到
这几道题目都属于源码泄露类的问题